

Xpathの表記方法をチェックしていただきたいです。
Xpath手書き入力でimportxml関数を実行すると、"インポートしたコンテンツは空です。"というエラーになる問題で困っています。
原因または解決策をご存知の方はいらっしゃいませんか。
##実験
私の行った手順は以下です。
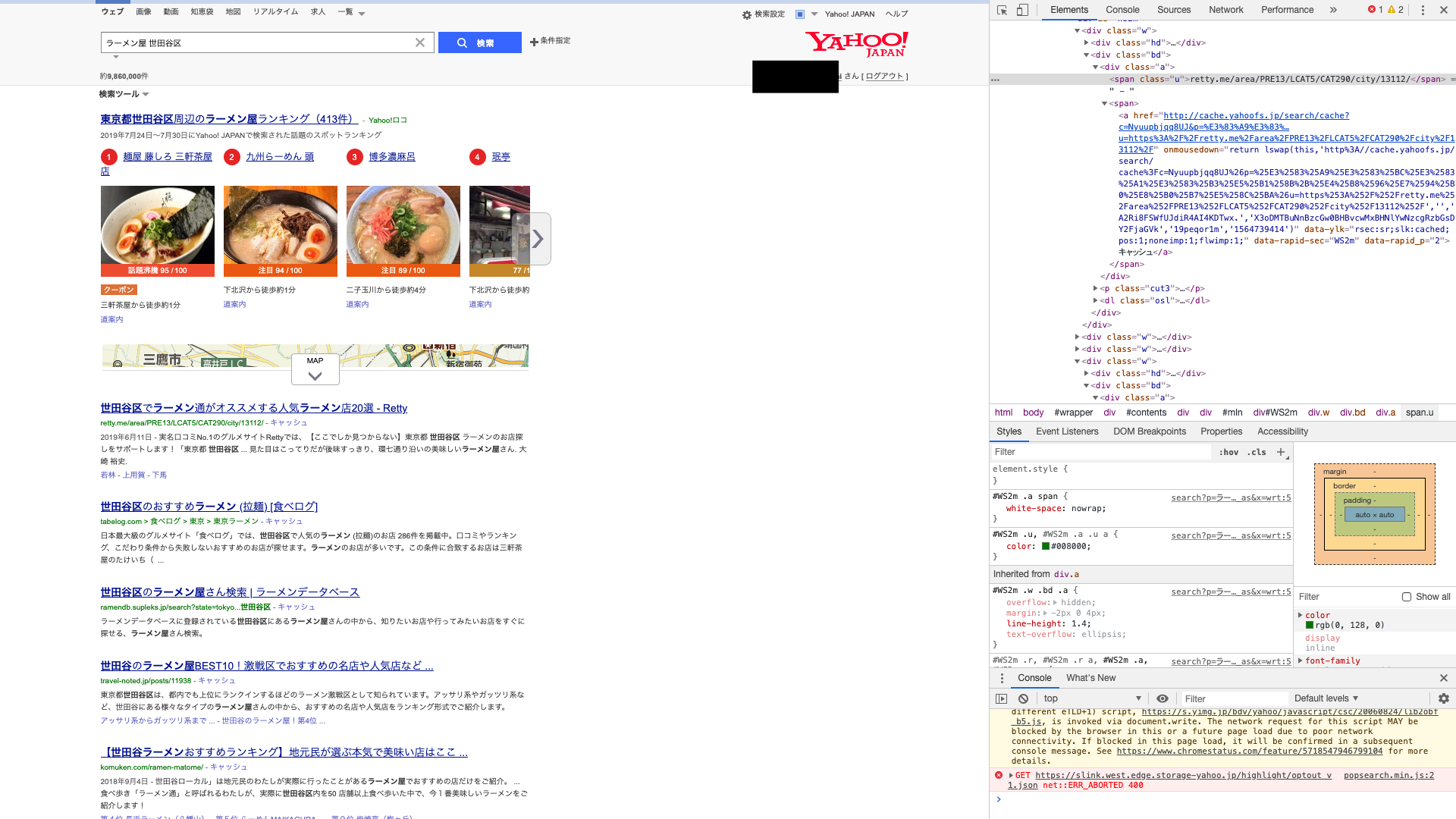
(1)Yahooの検索エンジンでワードを検索
(2)検証からXpathを手書きで記録
(3)Spread Sheet AppのimportXML関数に入力
すると、以下のような結果になりました。
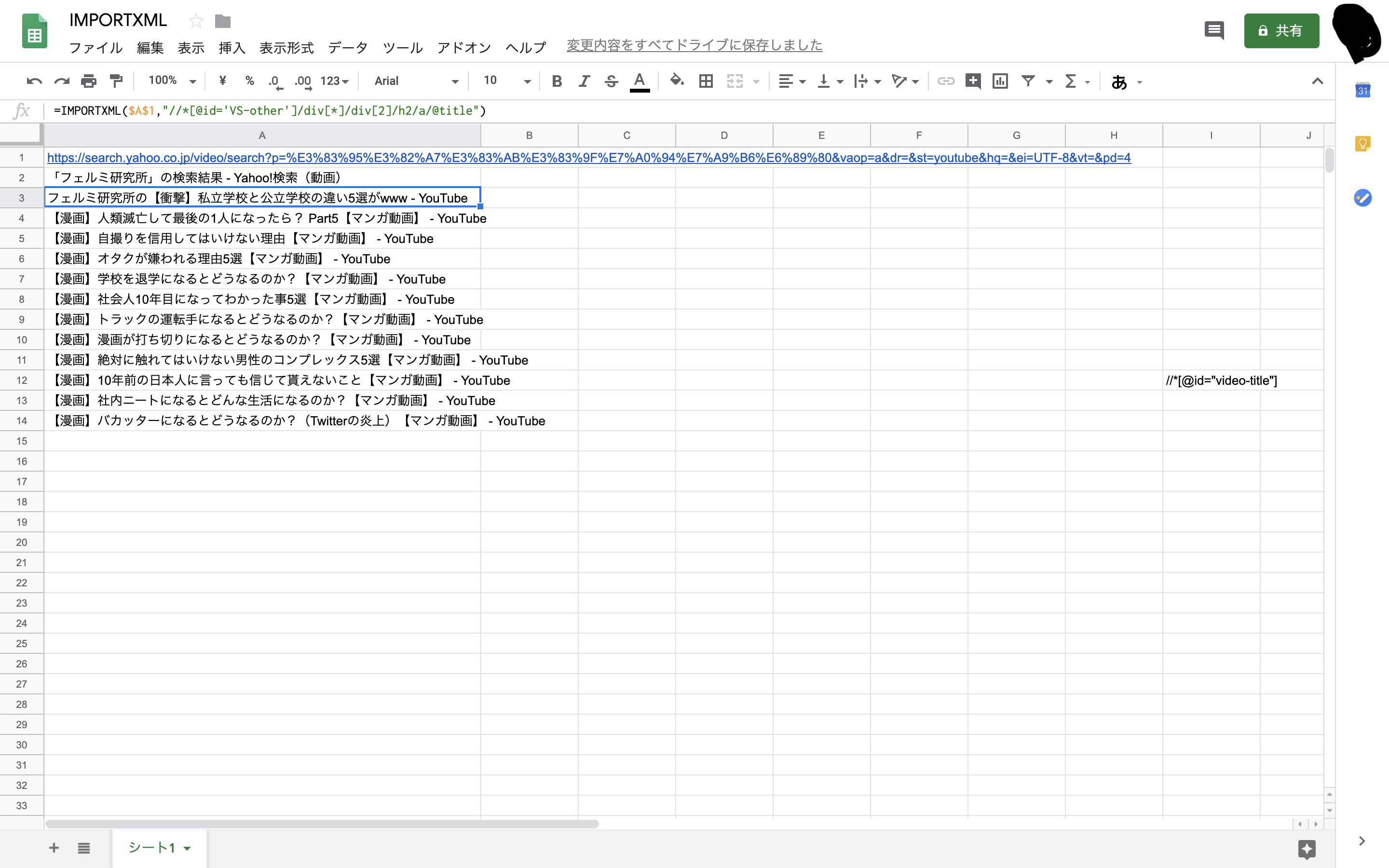
 ]
]

####私は【URLの部分だけ取得できる】と思ってました。
なぜなら、過去に同じ方法でYahoo動画検索の情報を取り込めたからです。
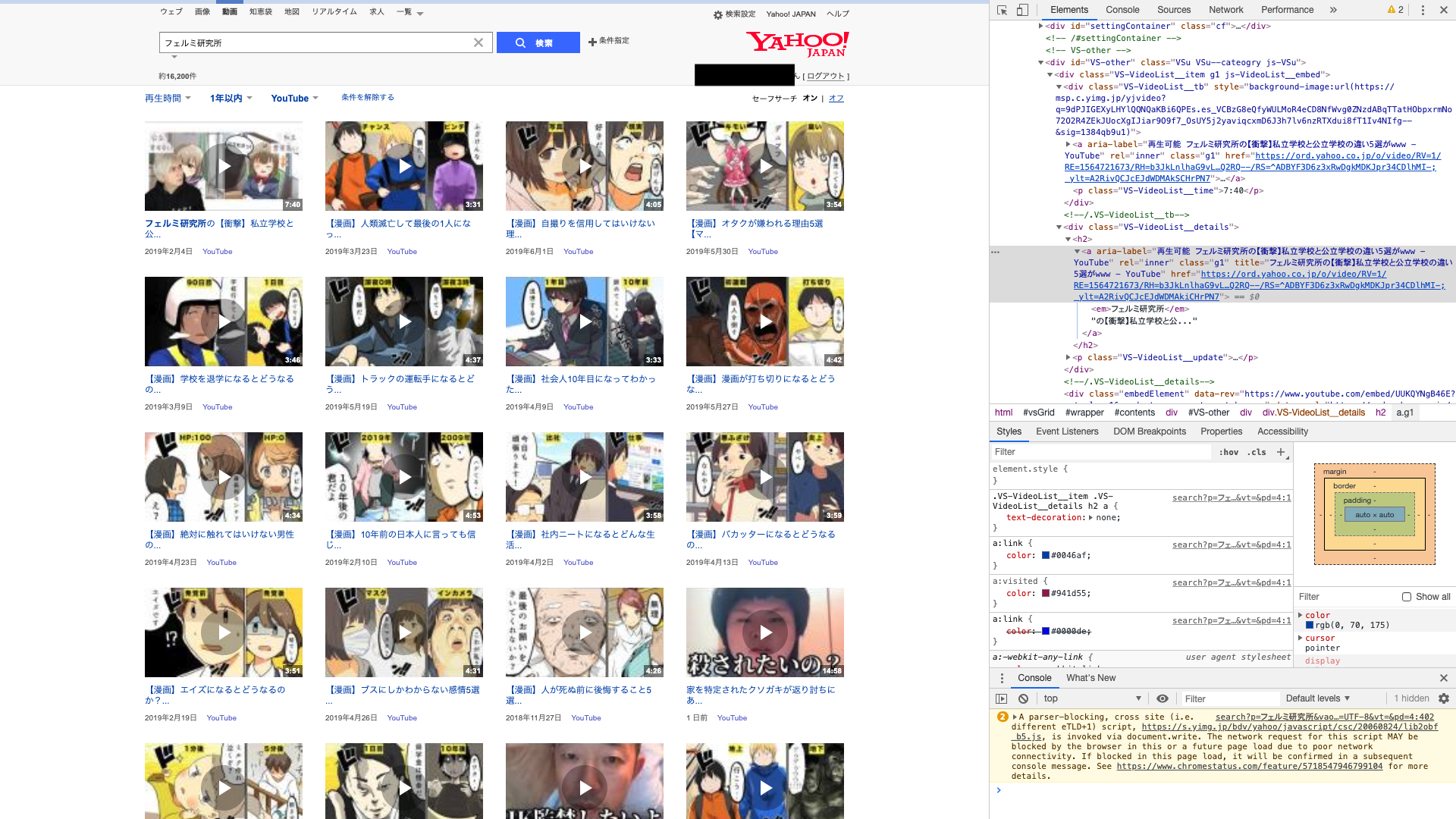
##検証
原因を確かめるため、以下のようなテストを行ってみましたが、
問題の解決には至りませんでした。
Xpathの変更
クラス名で指定 //*[@id='WS2m']/div[*]/div/span[@class='a']
[chrome]->[検証]->[Copy]->[CopyXpath] //*[@id="WS2m"]/div[1]/div[2]/div/span[1]
結果:同じエラーになる
##備考
taratailの同じような質問は一通り調べてみました。
静的サイトと動的サイトでできない場合があることは認知しています。
過去にYahooの動画検索で実行できているので、Yahooのサイトは静的サイトだと勝手に認識しています。
どなたか、XMLに精通している人がいらっしゃれば知恵を借りたいです。
回答1件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2019/08/07 03:56