

回答ありがとうございます。
それでエラーになってしまうので困っています。。。
リンク内容
こちらのサイトからゲームのタイトルと画像URLを取得したいです。
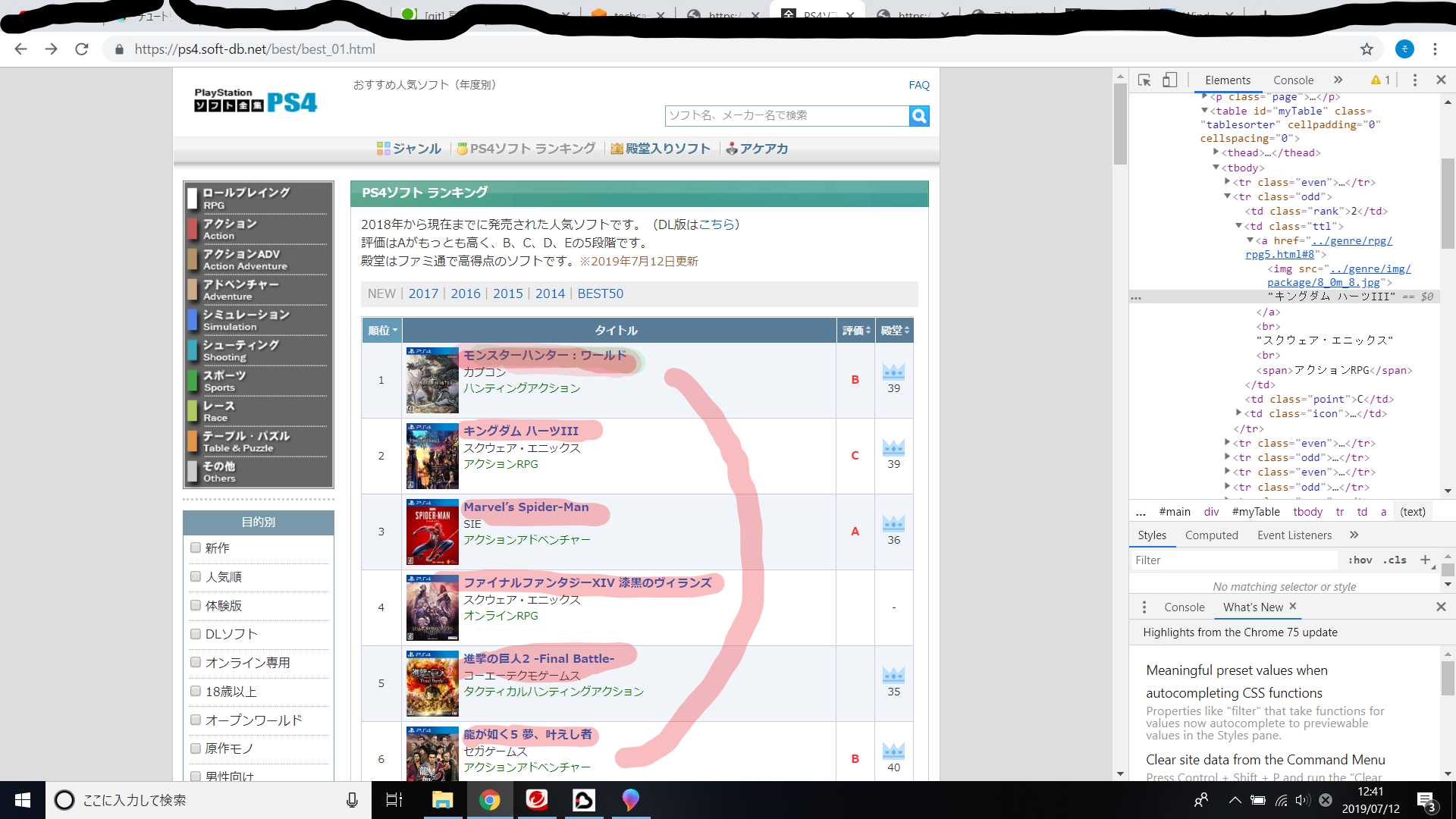
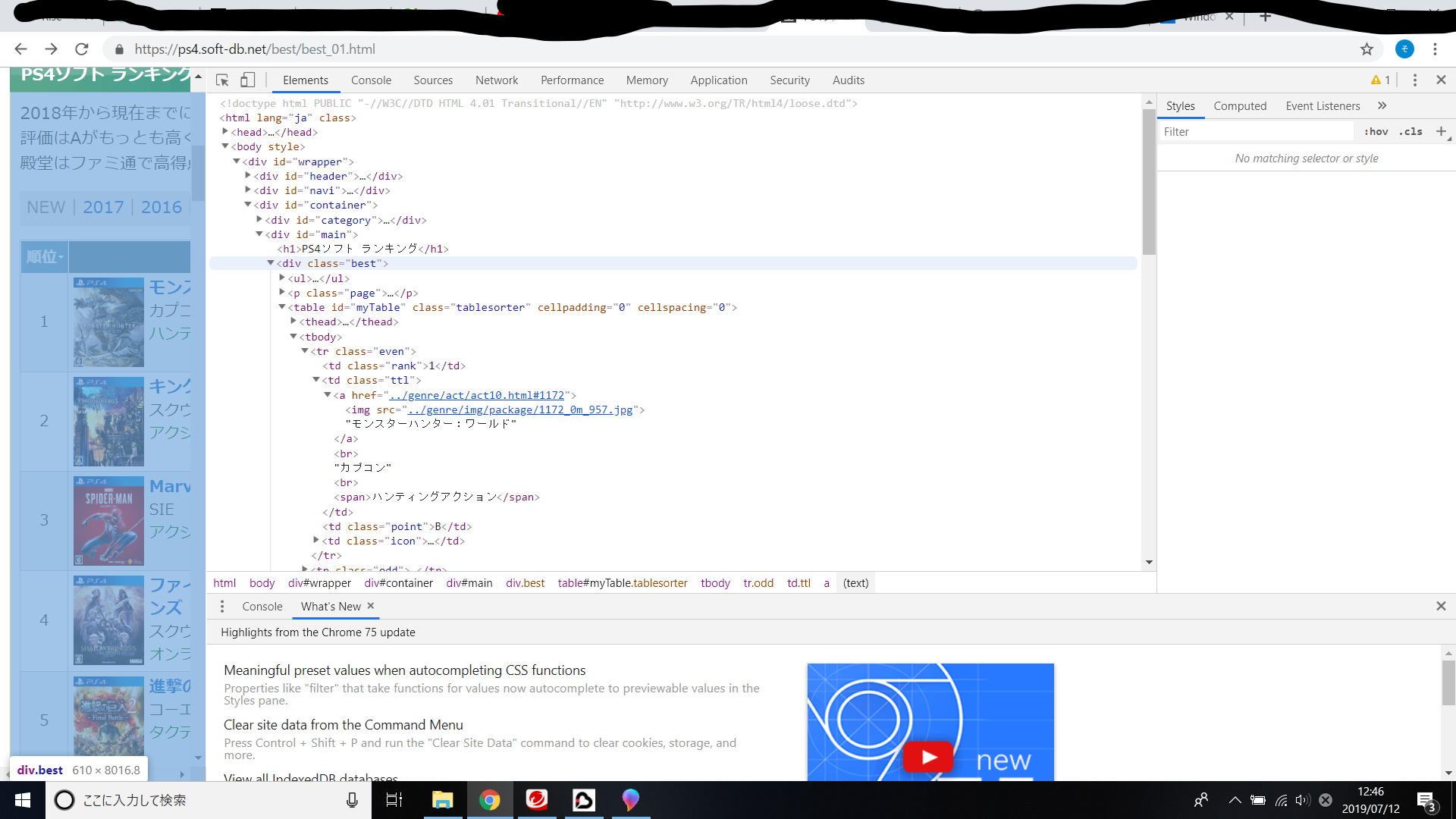
開発者ツールをみると
ゲームタイトルは
body < wraper < container < best < tbody < tr <a
の中にあることが分かったのですが
よく見ると
html
1 <a href="#"><img src="#">ゲームタイトル</a>
みたいな構造になっているので
ruby
1class Scraping 2 def self.movie 3 agent = Mechanize.new 4 page = agent.get("https://ps4.soft-db.net/best/best_01.html") 5 title = page.search('tbody tr .ttl a') 6 7 title.each do |a| 8 product = Product.new(title: a.inner_text) 9 product.save 10 end 11 end 12end
これでタイトルを取得することはできました。
しかし、画像URLを取得しようとすると
ruby
1class Scraping 2 def self.movie 3 agent = Mechanize.new 4 page = agent.get("https://ps4.soft-db.net/best/best_01.html") 5 image = page.at('tbody tr .ttl a img') 6 7 image.each do |b| 8 puts b.get_attribute('src') 9 end 10 11 end 12end
エラーになってしまいます
ただ URL部分だけを取得するためにつけている get_attributeをはずすをエラーになりません。
ruby
1class Scraping 2 def self.movie 3 agent = Mechanize.new 4 page = agent.get("https://ps4.soft-db.net/best/best_01.html") 5 image = page.at('tbody tr .ttl a img') 6 7 image.each do |b| 8 puts b.get_attribute('src') ←こいつをはずすと 9 end 10 11 end 12end
↑の結果
cmd
12.5.1 :001 > Scraping.movie 2src 3../genre/img/package/1172_0m_957.jpg 4 => [#<Nokogiri::XML::Attr:0x28e7a68 name="src" value="../genre/img/package/1172_0m_957.jpg">]
自力で解決できそうにないのでお願いします。
### 追記
ruby
1get_attribute('src') 2get_attribute(:src)
どちらでもエラーになります
回答2件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2019/07/12 05:49
2019/07/12 05:50