

前提・実現したいこと
htmlデータから特定の文字を抽出し、エクセルへ出力したいと考えています。
エクセルに出力したところ、エクセルにはA列に1文字しか入っていませんでした(添付1参照)。
やりたいこととして(添付2参照)、
A列の1行ごとに「名前」を入れたいのです。
htmlデータの<p class="d-chat_timeline-name"> 名 前(発信者)1 </p>の名前の部分には改行の記号は入っていません。
インターネットでも調べてみたのですが、該当するようなことが見つかりませんでした。
下記の構文にどのような構文を入れていけばいいのでしょうか。
アドバイスいただけると幸いです。どうぞよろしくお願いいたします。
<htmlデータ>
<div class="d-chat_timeline-post"> <p class="d-chat_timeline-name"> 名 前(発信者)1 </p> <ul class="d-chat_timeline-info"> <li>日付と時間1 </li> </ul> <div>名前1-1(受信者)<br /> 名前1-2(受信者)<br /> 名前1-3(受信者)<br /> 内容1</div>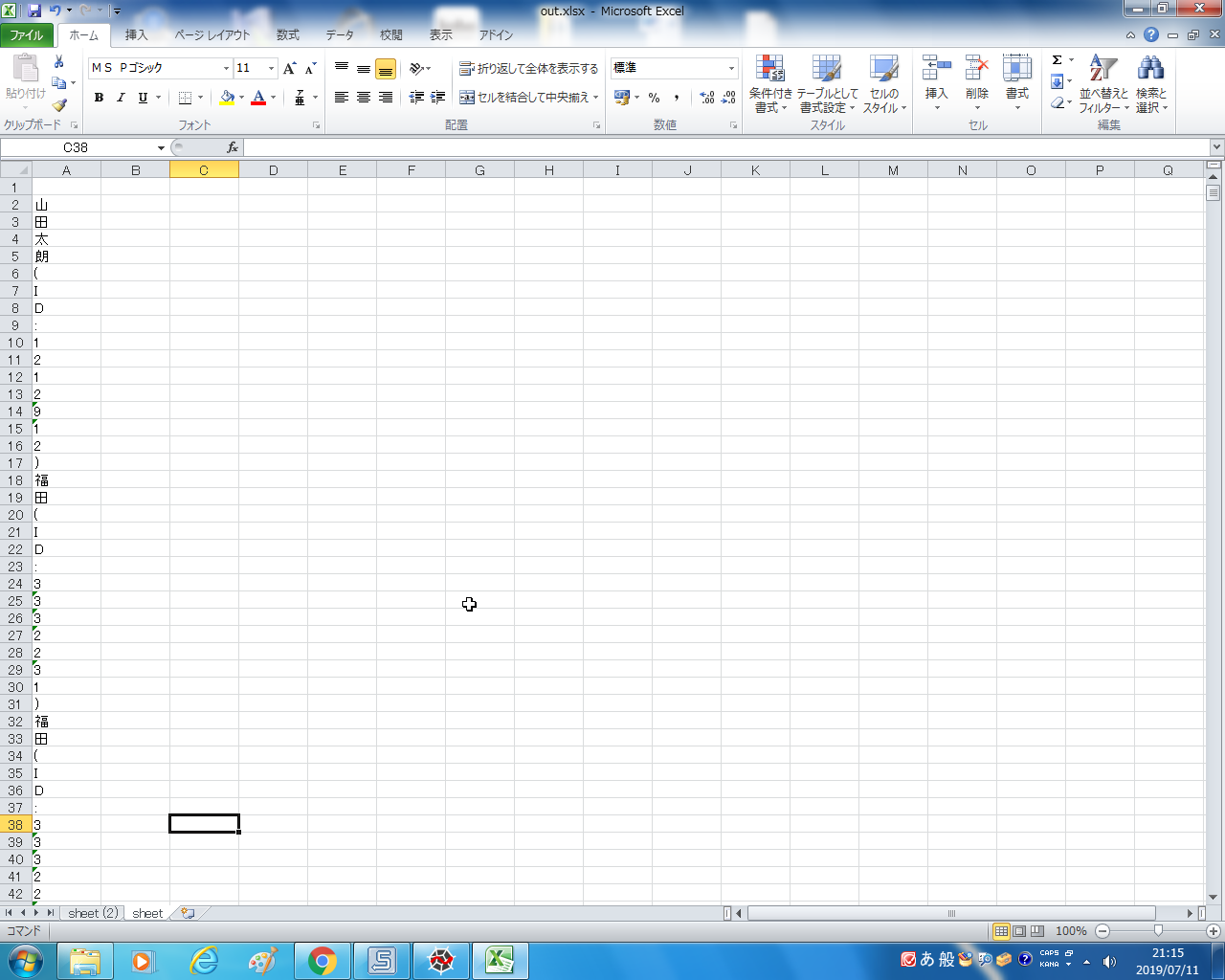

発生している問題・エラーメッセージ
pythonでのエラーメッセージはありませんが、エクセル出力データ(添付1、添付2参照)をお願いいたします。
該当のソースコード
python3.7
# -*- coding: utf-8 -*- """ Spyder Editor This is a temporary script file. """ import os, tkinter, tkinter.filedialog, tkinter.messagebox root = tkinter.Tk() root.withdraw() fTyp = [("","*.html")] file="/Users/XXXXXX/Desktop/message1.html" fd=open(file,"r",encoding="utf-8") res=fd.read() from bs4 import BeautifulSoup mojie=[] cur_pos=0 while True : target_tag = '<p class="d-chat_timeline-name">' closing_tag = '</p>' start_pos = res[cur_pos:].find(target_tag) end_pos = res[cur_pos:].find(closing_tag) if (start_pos == -1) or (end_pos == -1): break mojie += res[cur_pos + start_pos + len(target_tag) : cur_pos + end_pos] cur_pos = cur_pos + end_pos + len(closing_tag) import xlsxwriter wb = xlsxwriter.Workbook('/Users/XXXXXX/Downloads/out.xlsx') ws1 = wb.add_worksheet('sheet') i=0 for a in mojie: i=i+1 ws1.write(i, 0, a) wb.close()
試したこと
ここに問題に対して試したことを記載してください。
補足情報(FW/ツールのバージョンなど)
ここにより詳細な情報を記載してください。
回答1件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2019/07/11 19:04