

tiitoiさん回答ありがとうございます。
1.について
データ数が少ないことが主な原因なのかとは私も思いました。
しかし、始めはImageDataGeneratorを使わずに学習を行っていたのですが、そのときはepoch数とともにacc,val_accが上がり、loss,val_lossが下がっていました。
データ拡張のためにImageDataGeneratorを組み込んだプログラムを実行したところ、なんともうまくいかなくなってしまいました。その辺に原因はないでしょうか。
2.について
ありがとうございます。ImageDataGeneratorを使う場合はサンプル数が増えるのではないかとおもうのですが、その場合のステップ数はどのように指定すればよいのでしょうか。
3.について
転移学習ですね。さっそく試してみます。
acc,val_accを上げたい、loss,val_lossを下げたいです。
Python、機械学習および画像認識超初心者です。
自分で用意した2クラスの画像を、CNNで学習をして分類をするプログラムを書きたいと思いました。
1クラスにつき、訓練用に130枚ずつ、評価用に40枚ずつ、写真を撮って用意しました。下が用意した写真です。(2クラスなので合計260枚、80枚です)

それをgoogle drive に入れ、colaboratoryでマウントし、読み込んでいます。
見よう見まねでコードを書いて実行してみたのですが、acc,val_accが上がらず、loss,val_lossも下がりません。それらの値の変化をプロットしたグラフも振れ幅が大きく正しく学習を行えていると思えません。学習回数を増やしても同様の結果でした。
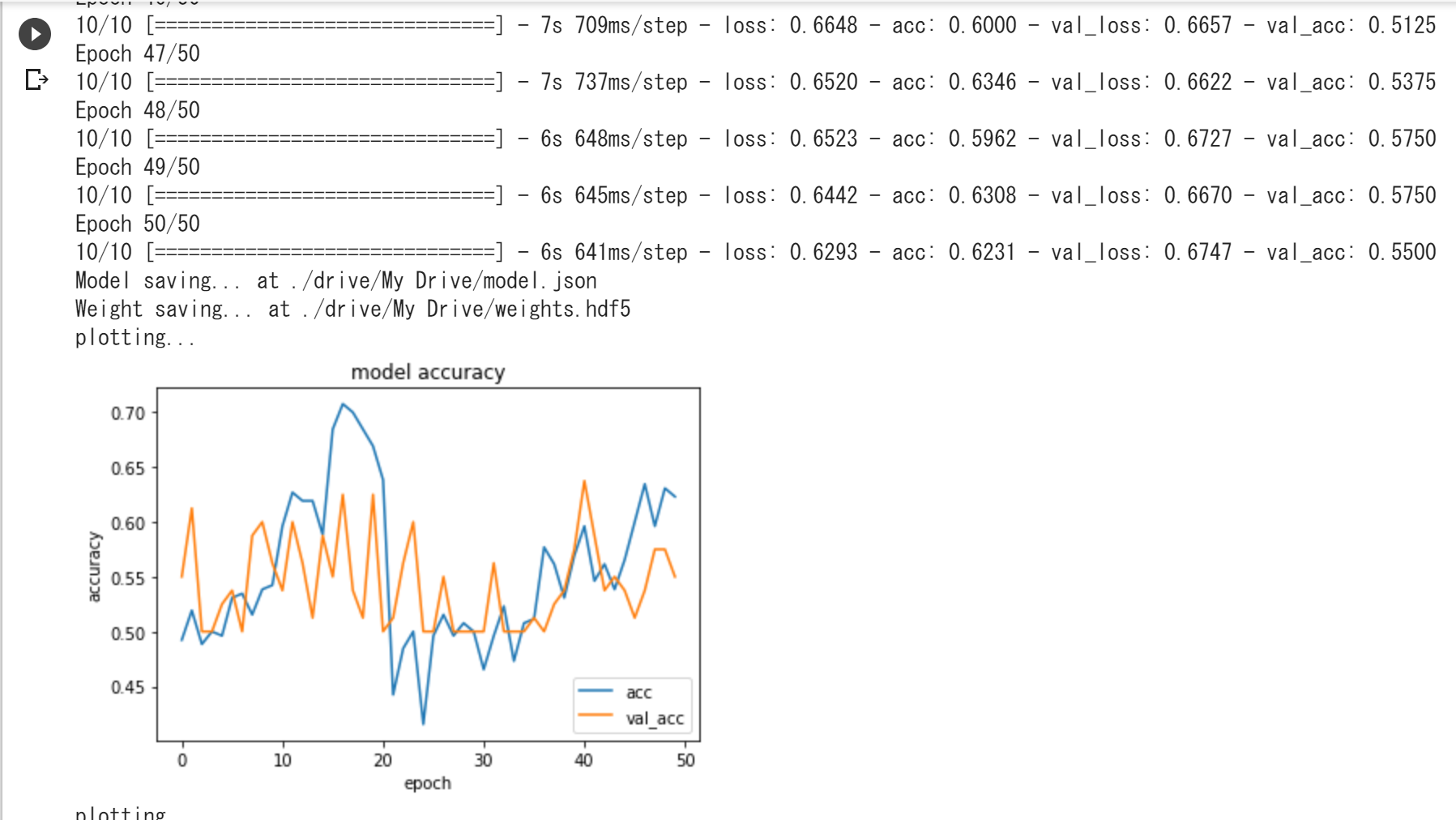

1.学習がうまくいかない原因
2.バッチサイズ、およびステップ数の決め方(今は決め方が分からなくて適当な値を入れています)
3.学習させるにはどうしたらよいのか
この3点について、ご教授お願いします。そのほかコードに変なところがあれば指摘いただきたいです。
発生している問題・エラーメッセージ
エラーメッセージ
該当のソースコード
from google.colab import drive drive.mount('/content/drive') from keras.models import Sequential, Model from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D, BatchNormalization num_classes = 2 img_height, img_width =64, 64 #モデルを定義 model = Sequential() model.add(Conv2D(32, (3, 3), padding='same', activation='relu', input_shape=(img_height, img_width, 3))) model.add(Conv2D(32, (3, 3), padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.5)) model.add(Conv2D(64, (3, 3), padding='same', activation='relu')) model.add(Conv2D(64, (3, 3), padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.5)) model.add(Flatten()) model.add(Dense(512, activation='relu')) model.add(Dropout(0.25)) model.add(Dense(num_classes)) model.add(Activation('softmax')) #ここなに? for layer in model.layers: layer.trainable = True from keras import optimizers model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True), metrics=['accuracy']) from keras.preprocessing.image import ImageDataGenerator train_datagen = ImageDataGenerator( rescale=1. / 255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, featurewise_center=True, featurewise_std_normalization=True, zca_whitening=True ) test_datagen = ImageDataGenerator( rescale=1. / 255, featurewise_center=True, featurewise_std_normalization=True, zca_whitening=True ) #訓練用データを作る train_generator = train_datagen.flow_from_directory( '/content/drive/My Drive/takekino/train', target_size=(img_height, img_width), batch_size= 26, #バッチサイズ分かりません class_mode='categorical') #検証用データ validation_generator = test_datagen.flow_from_directory( '/content/drive/My Drive/takekino/val', target_size=(img_height, img_width), batch_size= 8, #バッチサイズ分かりません class_mode='categorical') #学習 history = model.fit_generator( train_generator, steps_per_epoch=10, #これも適当です (訓練データサイズ)/(訓練バッチサイズ)? epochs=50, validation_data=validation_generator, validation_steps=10 #これも適当です (評価データサイズ)/(評価バッチサイズ)? ) # モデルを保存 print("Model saving... at ./drive/My Drive/model.json") from keras.utils import plot_model model_json = model.to_json() with open("./drive/My Drive/takekino_model.json", mode='w') as f: f.write(model_json) # 学習済みの重みを保存 print("Weight saving... at ./drive/My Drive/weights.hdf5") model.save_weights("./drive/My Drive/takekino_weights.hdf5") import matplotlib.pyplot as plt print("plotting...") plt.plot(history.history['acc']) plt.plot(history.history['val_acc']) plt.title('model accuracy') plt.xlabel('epoch') plt.ylabel('accuracy') plt.legend(['acc', 'val_acc'], loc='lower right') plt.show() print("plotting...") plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.title('model loss') plt.xlabel('epoch') plt.ylabel('loss') plt.legend(['loss', 'val_loss'], loc='upper right') plt.show()
試したこと
回答を受けてまずデータサンプル数を1クラスにつき訓練用200枚、評価用100枚(2クラスで400枚、200枚)に増やしました。
そのうえで、ImageDataGeneratorでの操作を色々変えてみました。
変更1.サンプル数を増やし、ImageDataGeneratorの操作はそのままにしたもの
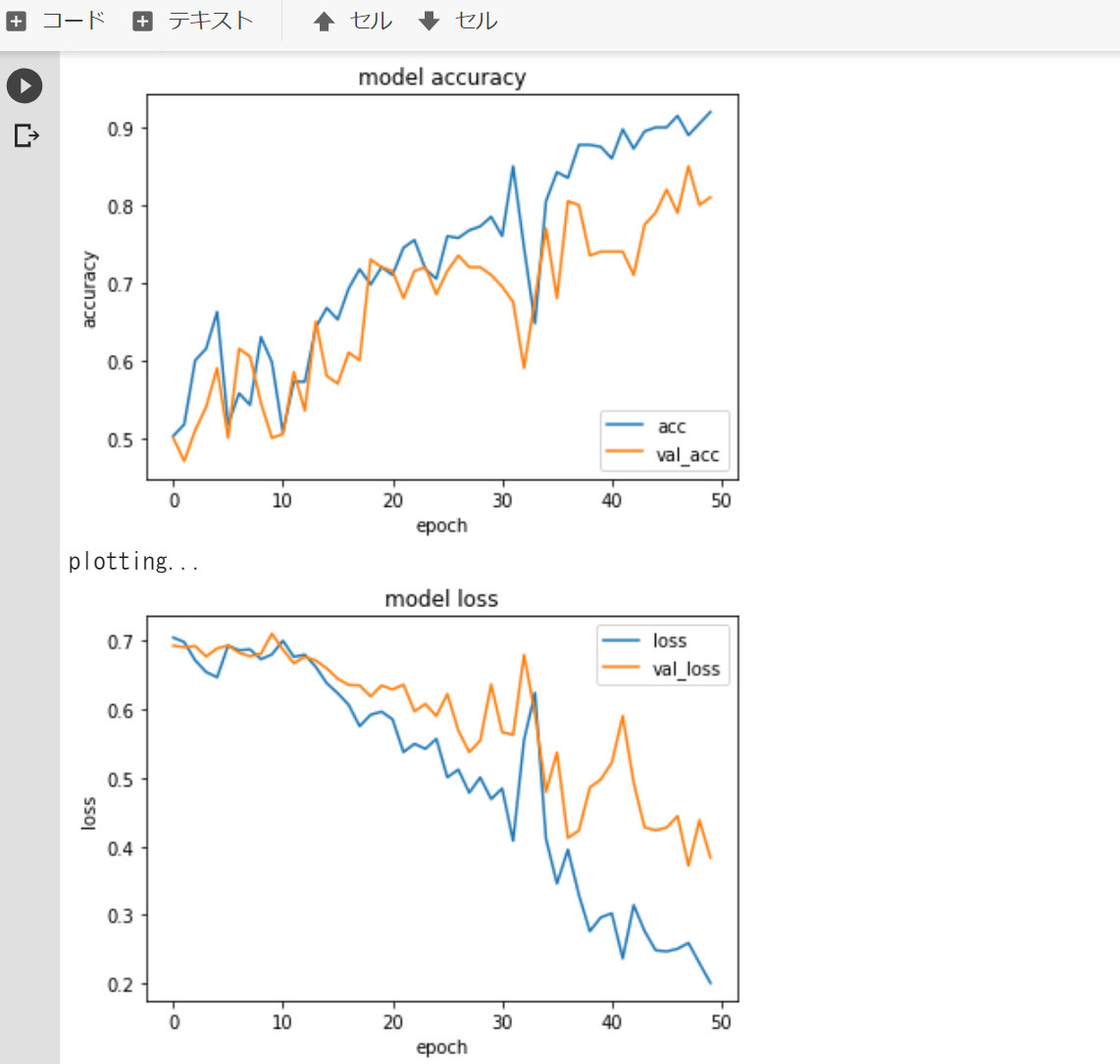
変更2.サンプル数を増やしImageDataGeneratorの操作を次のように変更したもの
train_datagen = ImageDataGenerator(
rescale=1. / 255,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(
rescale=1. / 255,
)

補足情報(FW/ツールのバージョンなど)
ここにより詳細な情報を記載してください。
回答2件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2019/05/08 03:56
2019/05/08 04:33
2019/05/08 11:52