

すいません「纏める」の部分を明確化しました。
各LabelごとにBeanNumber,Sumpleの列も含めて、それらをcsvファイルにして作成するという意味です。
もう一度質問の部分を明確に書き直したので、見ていただければ幸いです。
Pythonを使用して一つのCSVファイルを複数のCSVファイルに分割したいです。
(データセット下記)
| Label | Sumple | BeanNumber |
|---|---|---|
| img061c.jpg | くるみ豆 | B2 |
| img061c.jpg | くるみ豆 | B2 |
| img061c.jpg | くるみ豆 | B2 |
| ... | ||
| img065c.jpg | 五葉黒豆 | B6 |
| img065c.jpg | 五葉黒豆 | B6 |
| ... | ||
| img093c.jpg | 濃緑丸豆 | B39 |
| img093c.jpg | 濃緑丸豆 | B39 |
| img093c.jpg | 濃緑丸豆 | B39 |
| img093c.jpg | 濃緑丸豆 | B39 |
| img093c.jpg | 濃緑丸豆 | B39 |
このデータセットの各Label名ごとにデータを纏めて(Sumple,BeanNumbeを含めて)
各LabelごとにCSVファイルの作成を行いたいです。
Labelごと(img061c,img062c,img063c ... )下記のようなデータセットのイメージです。
| Label | Sumple | BeanNumber |
|---|---|---|
| img061c.jpg | くるみ豆 | B2 |
| img061c.jpg | くるみ豆 | B2 |
| img061c.jpg | くるみ豆 | B2 |
| ... | ||
| img061c.jpg | くるみ豆 | B2 |
| Label | Sumple | BeanNumber |
|---|---|---|
| img065c.jpg | 五葉黒豆 | B6 |
| img065c.jpg | 五葉黒豆 | B6 |
| img065c.jpg | 五葉黒豆 | B6 |
| ... | ||
| img065c.jpg | 五葉黒豆 | B6 |
| Label | Sumple | BeanNumber |
|---|---|---|
| img093c.jpg | 濃緑丸豆 | B39 |
| img093c.jpg | 濃緑丸豆 | B39 |
| img093c.jpg | 濃緑丸豆 | B39 |
| ... | ||
| img093c.jpg | 濃緑丸豆 | B39 |
label名ごとにデータをまとめてCSVファイルを作成する際には、そのファイル名はLabel名から".jpg"を削除し、新たに"New"を付けくわえ"img061cNew"というような形にCSVファイル名にしたいです。
コードをgyungyun545さんに修正して貰い、一応希望通りに動作させる事ができました。
しかしながら下記の写真のように拡張子のないファイルが生成されてしまいました。
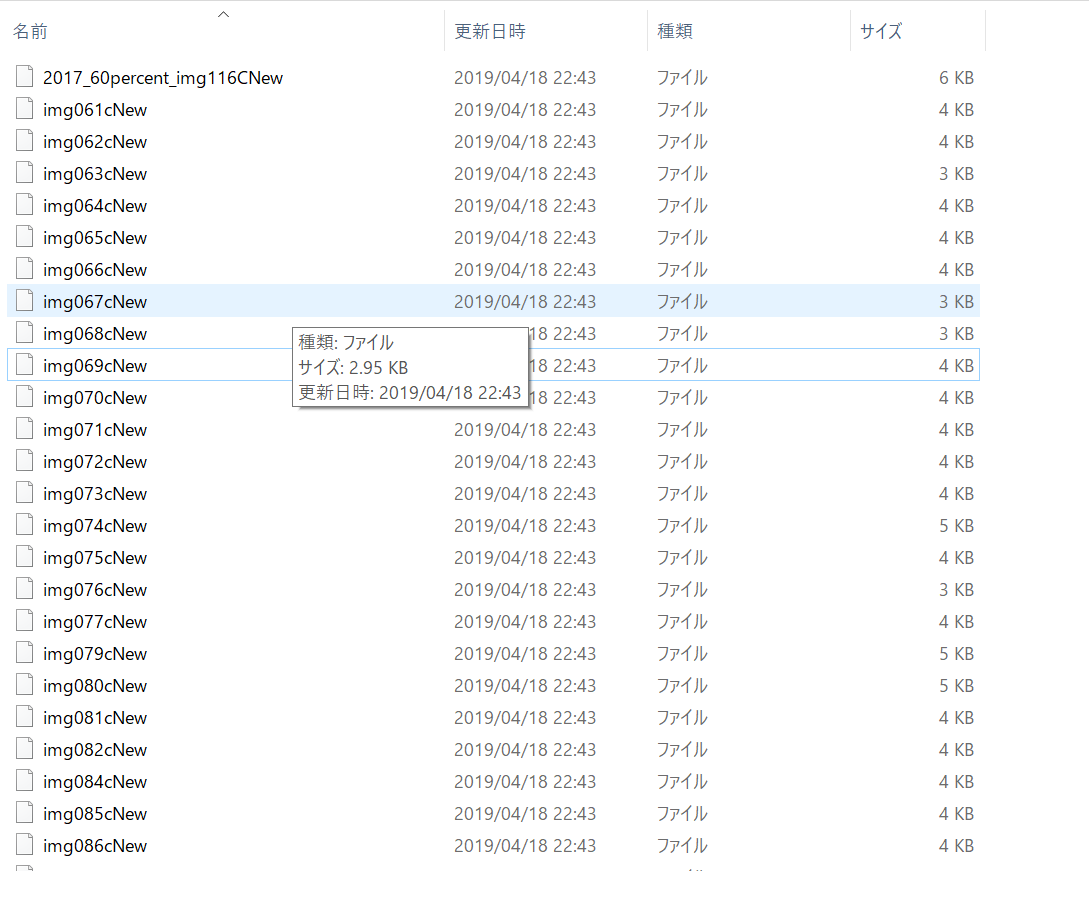
また実際にこのファイルをCSV形式で開いてみたところ、文字化けしていました。
またこれに関してはencodingを"utf-16"にした場合はエラーコードがこのような形になり、
Python
1'utf-16-le' codec can't decode bytes in position 42-43: illegal encoding
encodingを"utf-8"にした場合でもエラーでした。
Python
1'utf-8' codec can't decode byte 0x82 in position 0: invalid start byte
(これに関しては手作業でも一応修正できるのですが、生成されたファイルが100近くあり、可能であれば自動で修正したいです...)

Python
1import os 2import pandas as pd 3os.chdir("C:\Users\For Programming\Documents\Python Scripts") 4df1 = pd.read_csv('Native Been Analyze Side ver2 Re.csv', encoding="shift-jis") 5for Label in set(df1["Label"]): 6 df1[df1["Label"]==Label].to_csv(Label.replace(".jpg", "New"))
回答2件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2019/04/18 14:37
2019/04/19 01:23
2019/04/19 02:49 編集
2019/04/19 02:55