

TF_IDF = vecs.toarray()
terms = tfidf.get_feature_names()
for idx, word in zip(*np.where(TF_IDF> 0.4)):
text = print("INDEX:{}, WORD:{}, TF-IDF:{}".format(idx, terms[word], TF_IDF[(idx,word)]))
with open('key_Shiraz.txt','w') as f:
f.write(text)
と書くということでしょうか?
私は、あるjsonファイルを使用しています。
私のjsonファイルは、下のURLのjsonファイルでワインについてのレビューについてのデータで、多くの種類のワインのレビューについてリストとして記載されています。
'https://github.com/tulip-lab/sit742/raw/master/Assessment/2019/data/wine.json'
行には”country”,"variety", "price", "point", "description"などの項目があります。
私のjsonファイルは下のような表になります。(1行が1レビューになってます。)

このjsonファイルの”description”の列に含まれる単語でTF-IDF>0.4となるものを下のコードで出力しました。
python
1import pandas as pd 2from nltk.tokenize import RegexpTokenizer 3 4df = pd.read_json("wine.json") 5df2 = df.dropna(subset=['points','price']) 6with open('stopwords.txt') as f: 7 stop_words = f.read().splitlines() 8stop_words = set(stop_words) 9 10tokenizer = RegexpTokenizer(r"\w+(?:[-']\w+)?") 11 12def f(s): 13 tokens = tokenizer.tokenize(s) 14 return " ".join(word for word in tokens if word not in stop_words) 15 16df2["description"] = df2["description"].map(f) 17df2.to_json("result.json") 18 19df6 = pd.read_json("result.json") 20 21df7 = df2["description"] 22 23df8 = df6.query('variety == "Shiraz"') 24 25df9 = df8["description"] 26df9 27 28from sklearn.feature_extraction.text import TfidfVectorizer 29tfidf = TfidfVectorizer(analyzer='word', stop_words = 'english') 30 31vecs = tfidf.fit_transform(df9) 32 33TF_IDF = vecs.toarray() 34print(TF_IDF[TF_IDF>0.4]) 35 36import numpy as np 37 38TF_IDF = vecs.toarray() 39terms = tfidf.get_feature_names() 40for idx, word in zip(*np.where(TF_IDF> 0.4)): 41 print("INDEX:{}, WORD:{}, TF-IDF:{}".format(idx, terms[word], TF_IDF[(idx,word)]))
上のコードを出力すると、下のようなTF-IDF>0.4の単語の一覧とTF-IDFのそれぞれの値が出力されました。

これを'key_Shiraz.txt'という名前のテキストファイルに保存するために下のコードを入力しました。
pyton
1df10 = print("INDEX:{}, WORD:{}, TF-IDF:{}".format(idx, terms[word], TF_IDF[(idx,word)])) 2 3text = df10 4with open('key_Shiraz.txt','w') as f: 5 f.write(text)
しかし、'key_Shiraz.txt'のファイルには下の写真のようにTF-IDF>0.4の単語の一覧とTF-IDFのそれぞれの値が出力されておらず、一つの行しか保存されていませんでした。
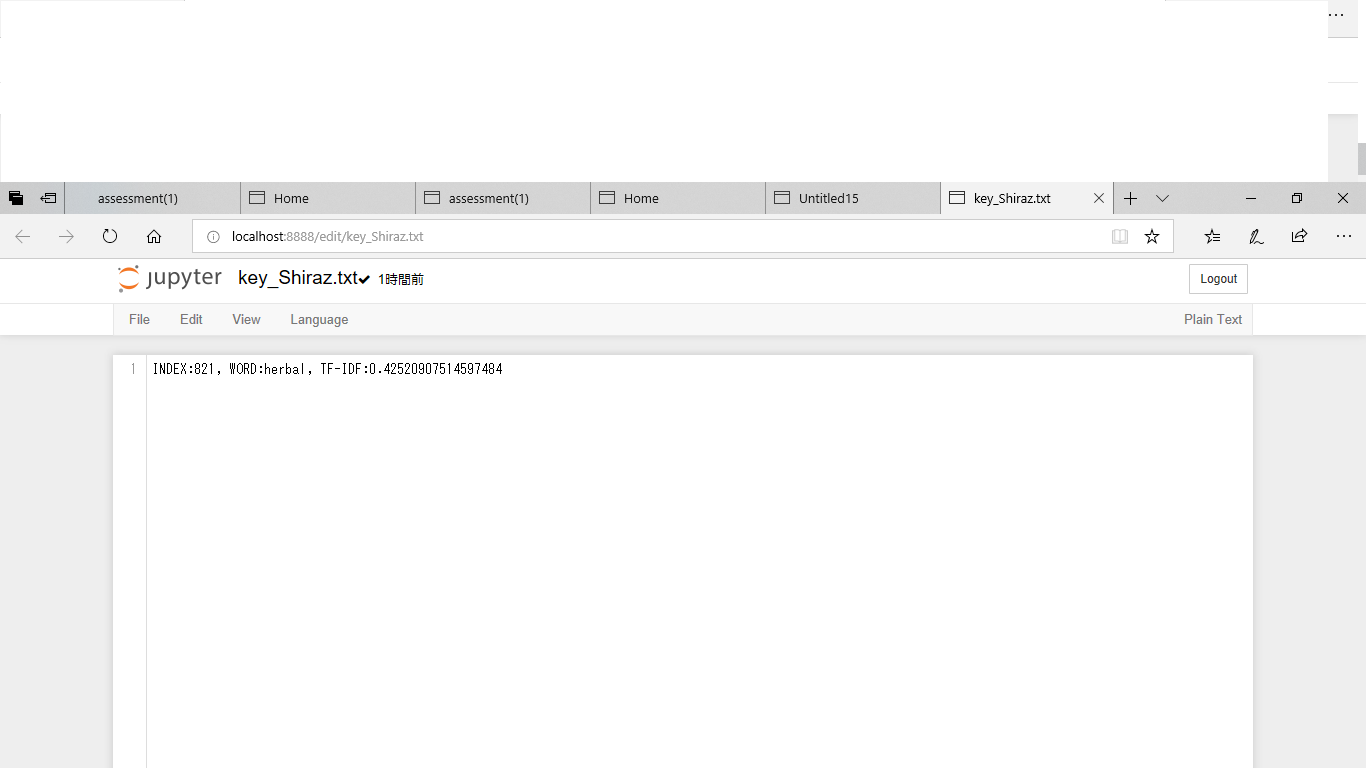
私が出力したすべてのTF-IDF>0.4の単語の一覧とTF-IDFのそれぞれの値を”key_Shiraz.txt”
に保存するためにはdf10をどのように定義すればよろしいのでしょうか。



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2019/04/05 07:12