

回答ありがとうございます。
RMSpropを使っているので学習率を変更してみます
最初は大きくして徐々に小さくする方が良さそうなのでLearningRateSchedulerも使ってみます。
収束に関しては収束しているかしていないかは、テストデータに対して満足できる結果が出ていればあまり意識する必要はないという理解でよいでしょうか?(ケースバイケースとは思いますが基本的な考え方として)
また評価指標については今回はテスト的に行っているのでaccを使っていますが、F値やAUCが一般的かと思います。
ドキュメントを見たところkerasでAUCなどを出す機能は標準ではないように感じたのですが、scikit-learnなどに渡して出すのが一般的なのでしょうか?
表題の件で質問させてください。
CNNを用いて画像の2値(正常/異常)分類を行っています。
いくつかモデルを作成したのですがその結果を受けてつぎはどのようなアプローチをすればよいのか分からず悩んでいます
使用しているフレームワークはkerasです。
データ数は以下の通りです。
正常画像 100枚
異常画像 100枚
訓練データ:120枚(正常:60枚、異常:60枚)
検証データ:40枚(正常:20枚、異常:20枚)
テストデータ:40枚(正常:20枚、異常:20枚)
精度指標:正解率(acc)
試した方法としては以下の3パターンです
①CNNでの分類
loss=0.14226582273840904
accuracy=0.9249999821186066

 ]
]
②データを水増ししたモデル
loss=0.22634971141815186
accuracy=0.9749999940395355


③水増し+バッチ正規化をしたモデル
loss=0.18287870474159718
accuracy=0.9249999821186066


精度やロスに関しては各エポック毎で一番良い結果(今回は検証データに対するロス)のモデルをスナップショットで保存したもので結果を出しています。
結果を見ると①と②のモデルはaccもlossも良さそうなのですがグラフの結果とは整合性が取れていないように感じます(まぐれで精度が良かっただけかも)
③に関してはaccもlossも訓練データ、検証データ共に良い結果が出せている箇所が見られます。
上記の結果から③に関しては他に比べるとマシなのかなとも感じるのですが、どのモデルも結果が収束している傾向が見られません(収束しているべきとの認識がすでに間違っていたらすいません)
これはパラメータの指定などで収束させることが出来る部分なのでしょうか?
また収束していない原因と考えられる部分はどこでしょうか?
↓収束しているイメージ
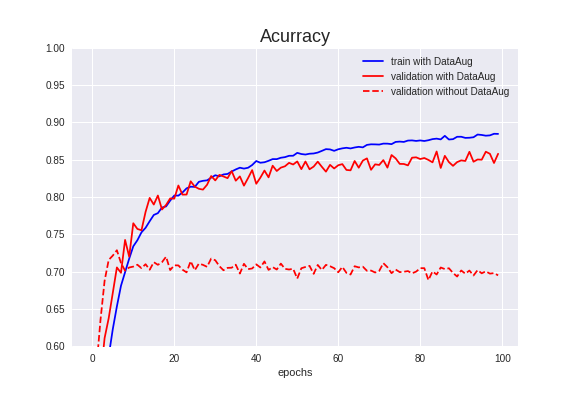
データ数やエポック数で変わる部分もありますし、何を持ってこれは良いモデルだとするかはビジネスケースにもよるとは思うのですが、スナップショットで一番いいところを保存したモデルでも、他のエポックでは精度が出ていない場合はそれは良いモデルと判断しても良いのでしょうか?
以下レイヤー定義、コンパイル、学習部分になります
一部のみ抜粋しているのであまり役に立たないかもしれません・・・
python
1from keras import layers 2from keras import models 3from keras import optimizers 4 5model = models.Sequential() 6#input_shape = CNNの入力テンソルが(image_height, image_width, image_channels)(バッチ次元を含まない)の形状 7model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(300, 300, 3))) 8model.add(layers.BatchNormalization()) 9model.add(layers.MaxPooling2D((2, 2))) 10 11model.add(layers.Conv2D(64, (3, 3), activation='relu')) 12model.add(layers.BatchNormalization()) 13model.add(layers.MaxPooling2D((2, 2))) 14 15model.add(layers.Conv2D(128, (3, 3), activation='relu')) 16model.add(layers.BatchNormalization()) 17model.add(layers.MaxPooling2D((2, 2))) 18 19model.add(layers.Conv2D(128, (3, 3), activation='relu')) 20model.add(layers.BatchNormalization()) 21model.add(layers.MaxPooling2D((2, 2))) 22 23model.add(layers.Conv2D(128, (3, 3), activation='relu')) 24model.add(layers.BatchNormalization()) 25model.add(layers.MaxPooling2D((2, 2))) 26 27model.add(layers.Flatten()) 28model.add(layers.Dense(512, activation='relu')) 29model.add(layers.BatchNormalization()) 30model.add(layers.Dense(1, activation='sigmoid')) 31 32model.compile(loss='binary_crossentropy', 33 optimizer=optimizers.RMSprop(lr=1e-4), 34 metrics=['acc']) 35 36history = model.fit_generator(train_generator, 37 steps_per_epoch = 6, 38 epochs = 30, 39 validation_data = validation_generator, 40 validation_steps = 5, 41 callbacks=[check_point])
回答2件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2019/03/11 07:16