

やりたいこと
python初心者です。
Kerasのlstmサンプルコード[https://github.com/keras-team/keras/blob/master/examples/lstm_text_generation.py]を参考に、diversityの値を一部変更し、複数ファイルを読み込めるように書き換えようとしています。
## ソースコード
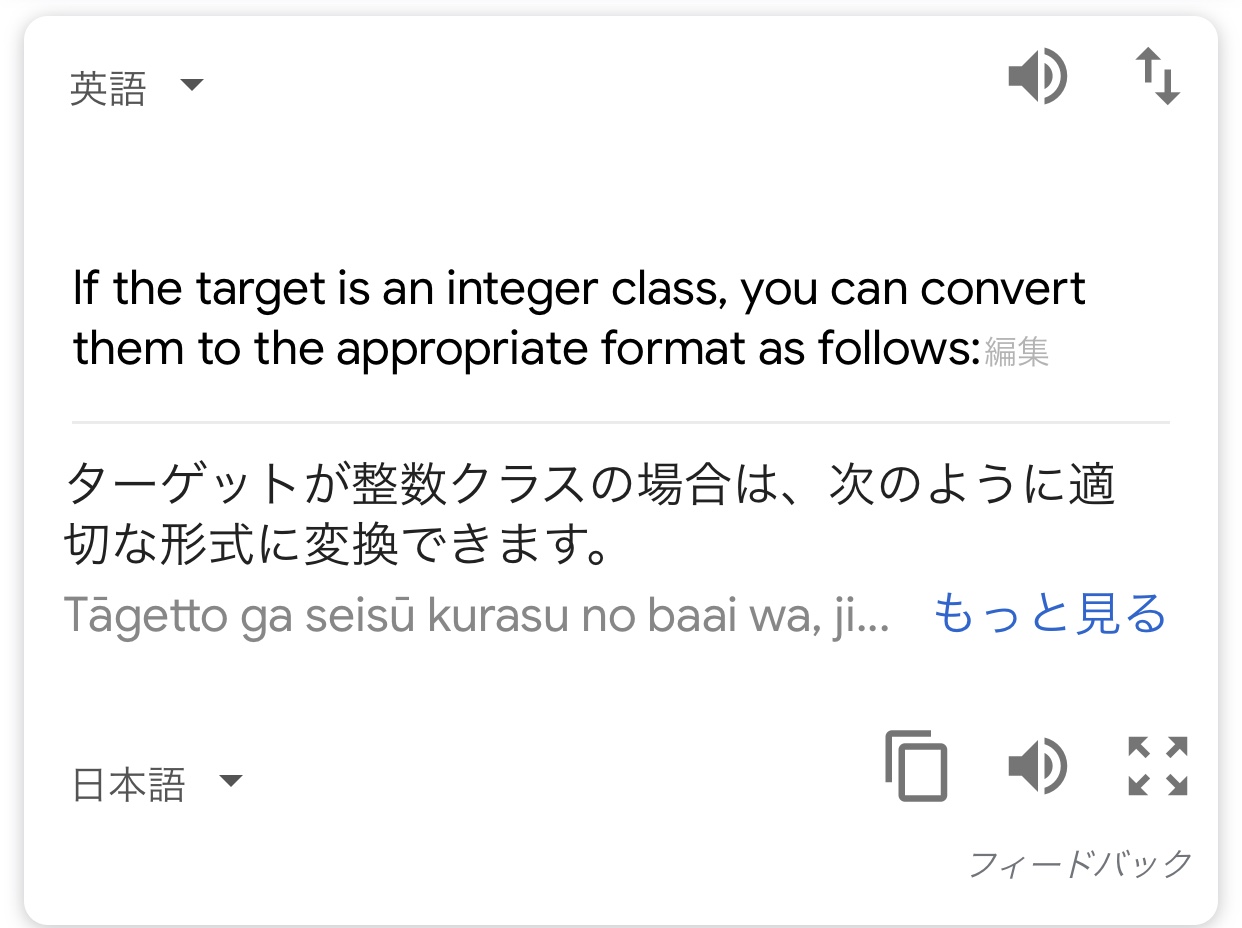
'''Example script to generate text from Nietzsche's writings. At least 20 epochs are required before the generated text starts sounding coherent. It is recommended to run this script on GPU, as recurrent networks are quite computationally intensive. If you try this script on new data, make sure your corpus has at least ~100k characters. ~1M is better. ''' from __future__ import print_function from keras.callbacks import LambdaCallback from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM from keras.optimizers import RMSprop from keras.utils.data_utils import get_file import numpy as np import random import sys import io data = [None] * 100 for i in range(100): with open('Data Folder/data001.txt'.format(i + 1), mode='r', encoding='utf-8') as f: data[i] = f.read() print('corpus length:', len(data)) chars = sorted(list(set(data))) print('total chars:', len(chars)) char_indices = dict((c, i) for i, c in enumerate(chars)) indices_char = dict((i, c) for i, c in enumerate(chars)) maxlen = 7 step = 3 sentences = [] next_chars = [] for i in range(0, len(data) - maxlen, step): sentences.append(data[i: i + maxlen]) next_chars.append(data[i + maxlen]) print('nb sequences:', len(sentences)) print('Vectorization...') x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool) y = np.zeros((len(sentences), len(chars)), dtype=np.bool) for i, sentence in enumerate(sentences): for t, char in enumerate(sentence): x[i, t, char_indices[char]] = 1 y[i, char_indices[next_chars[i]]] = 1 print('Build model...') model = Sequential() model.add(LSTM(128, input_shape=(maxlen, len(chars)))) model.add(Dense(len(chars), activation='softmax')) optimizer = RMSprop(lr=0.01) model.compile(loss='categorical_crossentropy', optimizer=optimizer) def sample(preds, temperature=1.0): # helper function to sample an index from a probability array preds = np.asarray(preds).astype('float64') preds = np.log(preds) / temperature exp_preds = np.exp(preds) preds = exp_preds / np.sum(exp_preds) probas = np.random.multinomial(1, preds, 1) return np.argmax(probas) def on_epoch_end(epoch, _): # Function invoked at end of each epoch. Prints generated text. print() print('----- Generating text after Epoch: %d' % epoch) start_index = random.randint(0, len(data) - maxlen - 1) for diversity in [0.2, 0.5, 0.8, 1.0]: print('----- diversity:', diversity) generated = '' sentence = data[start_index: start_index + maxlen] generated += sentence print('----- Generating with seed: "' + sentence + '"') sys.stdout.write(generated) for i in range(300): x_pred = np.zeros((1, maxlen, len(chars))) for t, char in enumerate(sentence): x_pred[0, t, char_indices[char]] = 1. preds = model.predict(x_pred, verbose=0)[0] next_index = sample(preds, diversity) next_char = indices_char[next_index] generated += next_char sentence = sentence[1:] + next_char sys.stdout.write(next_char) sys.stdout.flush() print() print_callback = LambdaCallback(on_epoch_end=on_epoch_end) model.fit(x, y, batch_size=128, epochs=60, callbacks=[print_callback]) ``` ## エラーコード ``` ValueError Traceback (most recent call last) <ipython-input-7-5103855688dc> in <module> 107 batch_size=128, 108 epochs=60, --> 109 callbacks=[print_callback]) ~\Anaconda3\envs\tensorflow16\lib\site-packages\keras\engine\training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, **kwargs) 950 sample_weight=sample_weight, 951 class_weight=class_weight, --> 952 batch_size=batch_size) 953 # Prepare validation data. 954 do_validation = False ~\Anaconda3\envs\tensorflow16\lib\site-packages\keras\engine\training.py in _standardize_user_data(self, x, y, sample_weight, class_weight, check_array_lengths, batch_size) 807 # using improper loss fns. 808 check_loss_and_target_compatibility( --> 809 y, self._feed_loss_fns, feed_output_shapes) 810 else: 811 y = [] ~\Anaconda3\envs\tensorflow16\lib\site-packages\keras\engine\training_utils.py in check_loss_and_target_compatibility(targets, loss_fns, output_shapes) 271 raise ValueError( 272 'You are passing a target array of shape ' + str(y.shape) + --> 273 ' while using as loss `categorical_crossentropy`. ' 274 '`categorical_crossentropy` expects ' 275 'targets to be binary matrices (1s and 0s) ' ValueError: You are passing a target array of shape (31, 1) while using as loss `categorical_crossentropy`. `categorical_crossentropy` expects targets to be binary matrices (1s and 0s) of shape (samples, classes). If your targets are integer classes, you can convert them to the expected format via: from keras.utils import to_categorical y_binary = to_categorical(y_int) Alternatively, you can use the loss function `sparse_categorical_crossentropy` instead, which does expect integer targets. ``` ## 分からないこと エラーコード内の ``` from keras.utils import to_categorical y_binary = to_categorical(y_int) ``` このコードを改良すれば治る、ということなのでしょうか。 エラーが何を指してのものかすら分かっていない状態です。 このValueErrorの原因と対処法について、教えてください。
回答1件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
退会済みユーザー
2019/02/03 08:23
2019/02/03 08:42
退会済みユーザー
2019/02/03 09:24
2019/02/03 22:14
退会済みユーザー
2019/02/04 11:09
2019/02/05 22:43
退会済みユーザー
2019/02/06 10:35
2019/02/06 22:44
退会済みユーザー
2019/02/07 05:27