

何度もお願いしていますが、Python対応不可なので回答依頼しないでください(そろそろ迷惑です)。その分、あなたは回答の機会を失していることになります。
下記のようなコードを書きました.
今私がしたいことはvtkファイルというものをつくろうと思っています.
remove_history_7702-15402_3points.csvには7000行100列のデータが入っています.
1列ごとにそのタイムステップの各座標の値があります.
その1列ずつの値と,xyz_7702-15402_3ponts.csvの座標を結び付けるのですが,,,よく分かりません.
1列のみのときは成功しました.コートが載せてあります.
用は,100列のデータを1列ずつ取り出して,for文かなにかで
100個の7702-15402_3points_3delta_(k+1)step.vtkというファイルを作りたいのです.
どなたかご教授お願いします.
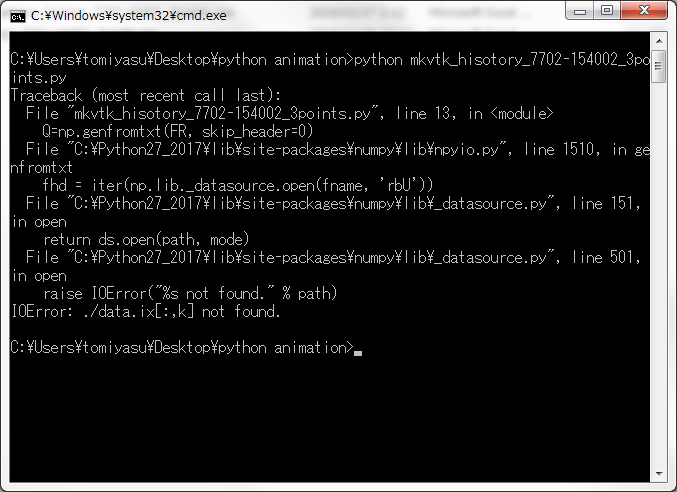
これがコードを回したときのエラーの出力です.
###今回書いて失敗したコード
iimport pyvtk import numpy as np import pandas as pd FR="./xyz_7702-15402_3ponts.csv" XYZ=np.genfromtxt(FR, delimiter=",", skip_header=0) data = pd.read_csv("remove_history_7702-15402_3points.csv").values.tolist() for k in range(100): #colum = data[:,k] FR="./data.ix[:,k]" Q=np.genfromtxt(FR, skip_header=0) ## X と Y の座標の数を取得 XMAX=len(np.unique(XYZ[:,0])) YMAX=len(np.unique(XYZ[:,2])) ### polygon の構成ノードを格納 polygon= [[ XMAX*(i)+j, XMAX*(i+1)+j, XMAX*(i+1)+j+1, XMAX*(i)+j+1] for i in range(YMAX-1) for j in range(XMAX-1) ] structure=pyvtk.PolyData(points=XYZ, polygons=polygon) pointdata = pyvtk.PointData(pyvtk.Scalars(Q, name='point-scalar', lookup_table='default')) vtk = pyvtk.VtkData( structure, "# test", pointdata) vtk.tofile('7702-15402_3points_3delta_(k+1)step')
###cscが1列の時:成功したコード
#!/usr/bin/env python2.7 # coding: utf-8 # test.py import pyvtk import numpy as np FR="./xyz_1-7701_3ponts.csv" XYZ=np.genfromtxt(FR, delimiter=",", skip_header=0) FR="./rmv_1-7701_3points_3delta.csv" Q=np.genfromtxt(FR, skip_header=0) ## X と Y の座標の数を取得 XMAX=len(np.unique(XYZ[:,1])) YMAX=len(np.unique(XYZ[:,2])) ### polygon の構成ノードを格納 polygon= [[ XMAX*(i)+j, XMAX*(i+1)+j, XMAX*(i+1)+j+1, XMAX*(i)+j+1] # LL, LR, UR, UL の順番。 端を除外 for i in range(YMAX-1) for j in range(XMAX-1) ] structure=pyvtk.PolyData(points=XYZ, polygons=polygon) pointdata = pyvtk.PointData(pyvtk.Scalars(Q, name='point-scalar', lookup_table='default')) vtk = pyvtk.VtkData( structure, "# test", pointdata) vtk.tofile('1-7701_3points_3delta')
回答2件
あなたの回答
tips
プレビュー


