

前提・実現したいこと
Twitterのタイムラインから"summer"という単語を含んだツイートのみを取得し、
トピック分析を行なった上で解析結果を可視化しています。
発生している問題・エラーメッセージ
以下の結果が取得できたのですが、
実行したコードで理解できていない箇所があります。
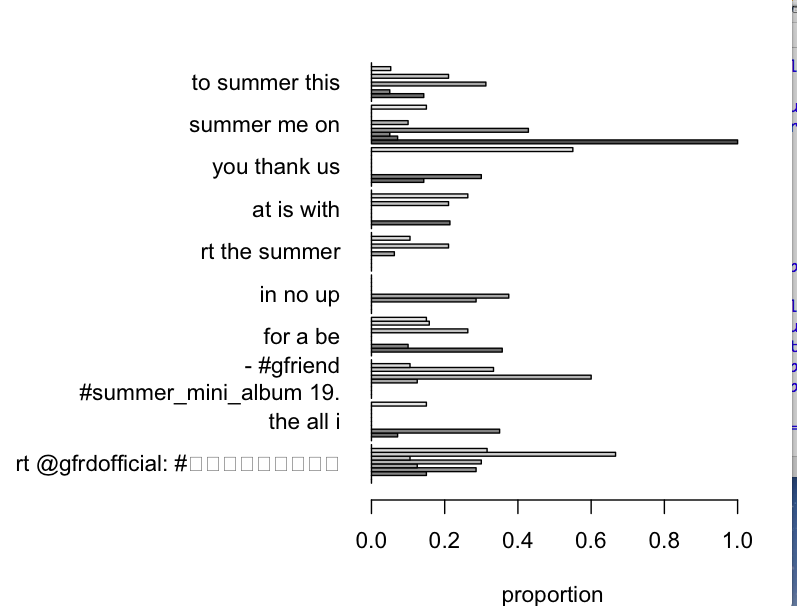
①結果のグラフについて
LDAの理論を理解できていないので、
まず、結果の横軸について、proportionの値の意味がわかりません。
また、グラフにおいては各トピックについて10個の棒グラフが現れる範囲が確保されていますが、
これは取得した最初の10個のツイートをそれぞれ表しているのでしょうか。
②以下、該当のソースコードでコメントアウトに明記させていただきました。
お手数ですが、該当のソースコードを参照願います。
該当のソースコード
R
1library(twitteR) 2library(lda) 3 4tweets <- twListToDF(searchTwitter("summer", lang="en", n=100)) 5tweets$text <- iconv(tweets$text, to ="utf-8-mac") 6tweets$text <- gsub("https://.*", "", tweets$text) 7 8sentence <- tweets$text 9#ここで何をやっているのか分からない 10lex <- lexicalize(sentence, lower = TRUE) 11 12#10個のトピックを作成している方法が分からない 13k <- 10 14result <- lda.collapsed.gibbs.sampler(lex$documents, k, lex$vocab, length(tweets$text), 0.1, 0.001) 15 16#上位語を作成しているが、どのように作成しているのか分からない 17top.words <- top.topic.words(result$topics, 3, by.score=TRUE) 18 19#最初の10個のツイートだけ解析しているが、それは観測データの標本として取得し、母集団の性質を明らかにするために用いられるのか 20N <- 10 21topic.proportions <- t(result$document_sums) / colSums(result$document_sums) 22topic.proportions <- topic.proportions[1:N, ] 23topic.proportions[is.na(topic.proportions)] <- 1/n 24 25#作成したグラフの読み方が分からない 26colnames(topic.proportions) <- apply(top.words, 2, paste, collapse=" ") 27par(mar=c(4, 14, 2, 2)) 28barplot(topic.proportions, beside=TRUE, horiz=TRUE, las=1, xlab="proportion") 29
補足情報(FW/ツールのバージョンなど)
R 3.4.0
回答1件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。