結論から言いますと、正しくないようです。
参考:B+Tree Insertions
B+木は、索引部とデータ部が分かれているデータ構造で、データは末端ノードで管理されます。初期状態の図が課題の図だとすると、四角で表されているのがノードで、丸四角で表されているのがデータと思います。ここで、末端ノードと索引ノードの区別が必要と思います。
今回は、同じ構造を末端ノードと索引ノードとして使用しているようです。この四角の構造を見てみると、インデクス値を格納できる場所が2つ、ポインタを格納できる場所が3つの構造になっています。この構造の使われ方は、末端ノードと索引ノードで違っています。
末端ノードとして使うときは左から順に
- 未使用、または1つ目のデータへのポインタ
- 1つ目のデータのインデクス値
- 未使用、または2つ目のデータへのポインタ
- 2つ目のデータのインデクス値
- 未使用、または次の末端ノードへのポインタ
索引ノードとして使うときは左から順に
- 未使用、または1つ目の子ノードのインデクス値よりも小さい子ノードへのポインタ
- 1つ目の子ノードの最小インデクス値
- 未使用、または1つ目の子ノードへのポインタ
- 2つ目の子ノードの最小インデクス値
- 未使用、または2つ目の子ノードへのポインタ
おそらく、回答は以下のような形だろうと思います。たたし、分割時のロジックはいろいろ流派があるようです。ここではYouTubeの例のようにシンブルに1/2に分け、二つ目ノードのインデクス値で親ノードを作る方法にしました。
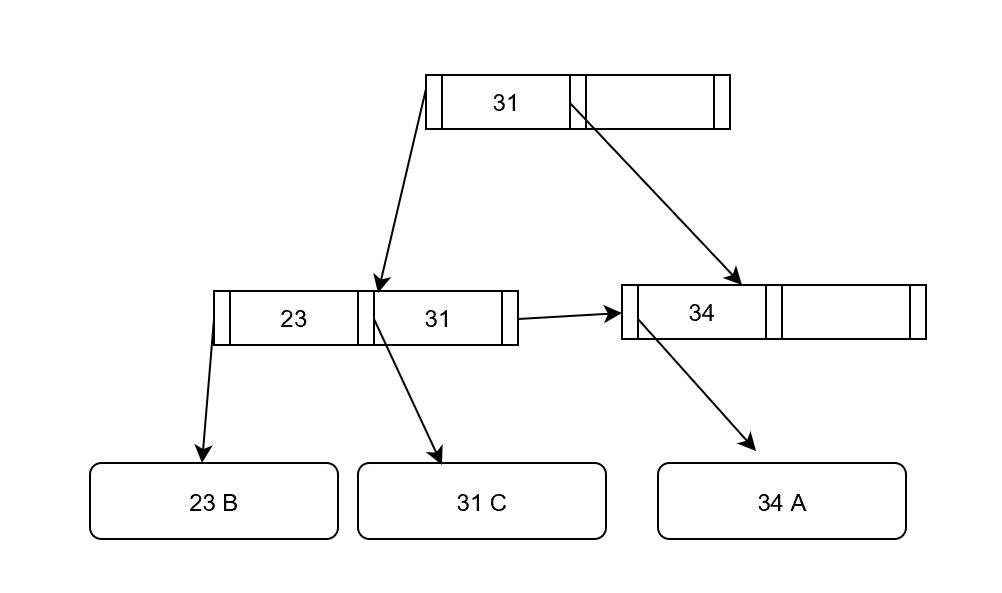
初期状態
[23 B]を挿入(部屋が空いてるのでそのまま格納)
[31 C]を挿入(オーバーしたので分割し、親ノードを生成)
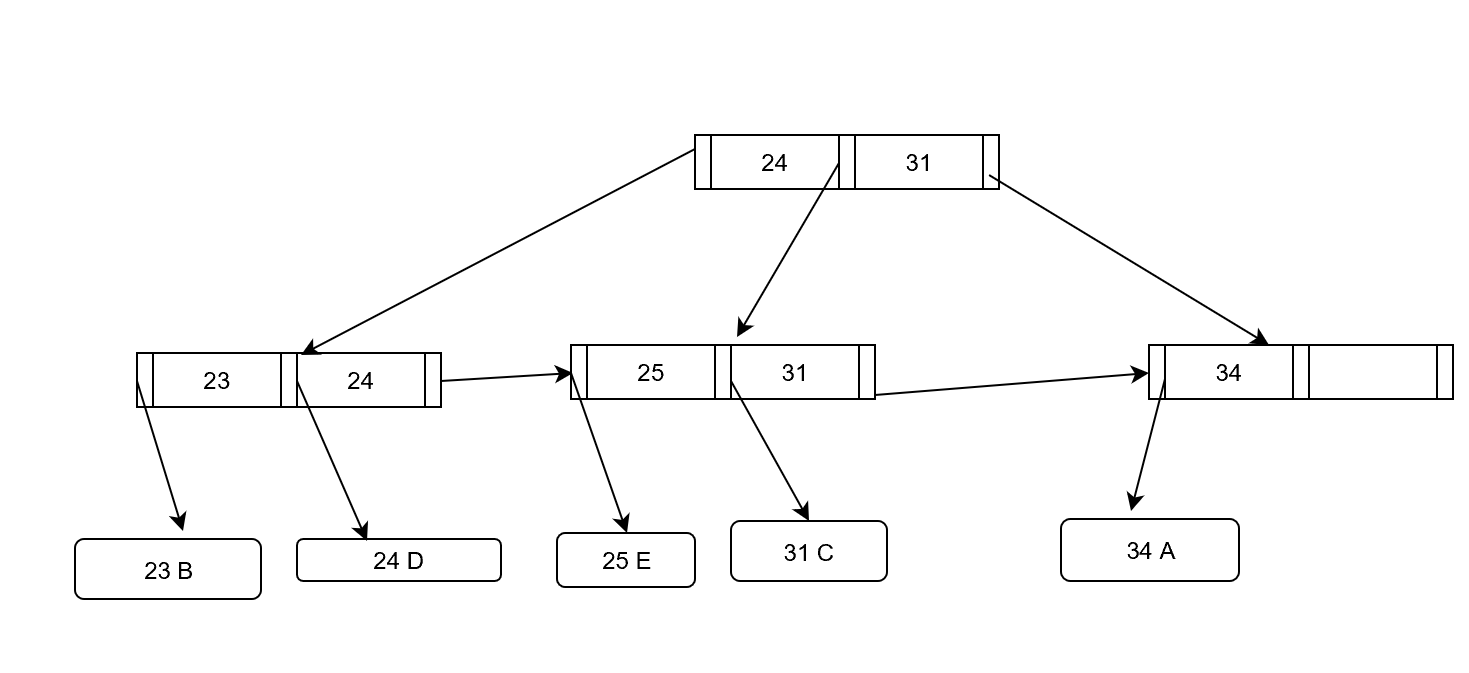
[24 D]を挿入(部屋が空いてるのでそのまま格納)
[25 E]を挿入(オーバーしたので分割し、親ノードにインデクス追加)
[24,31]
[23,][24, 25][31, 34]
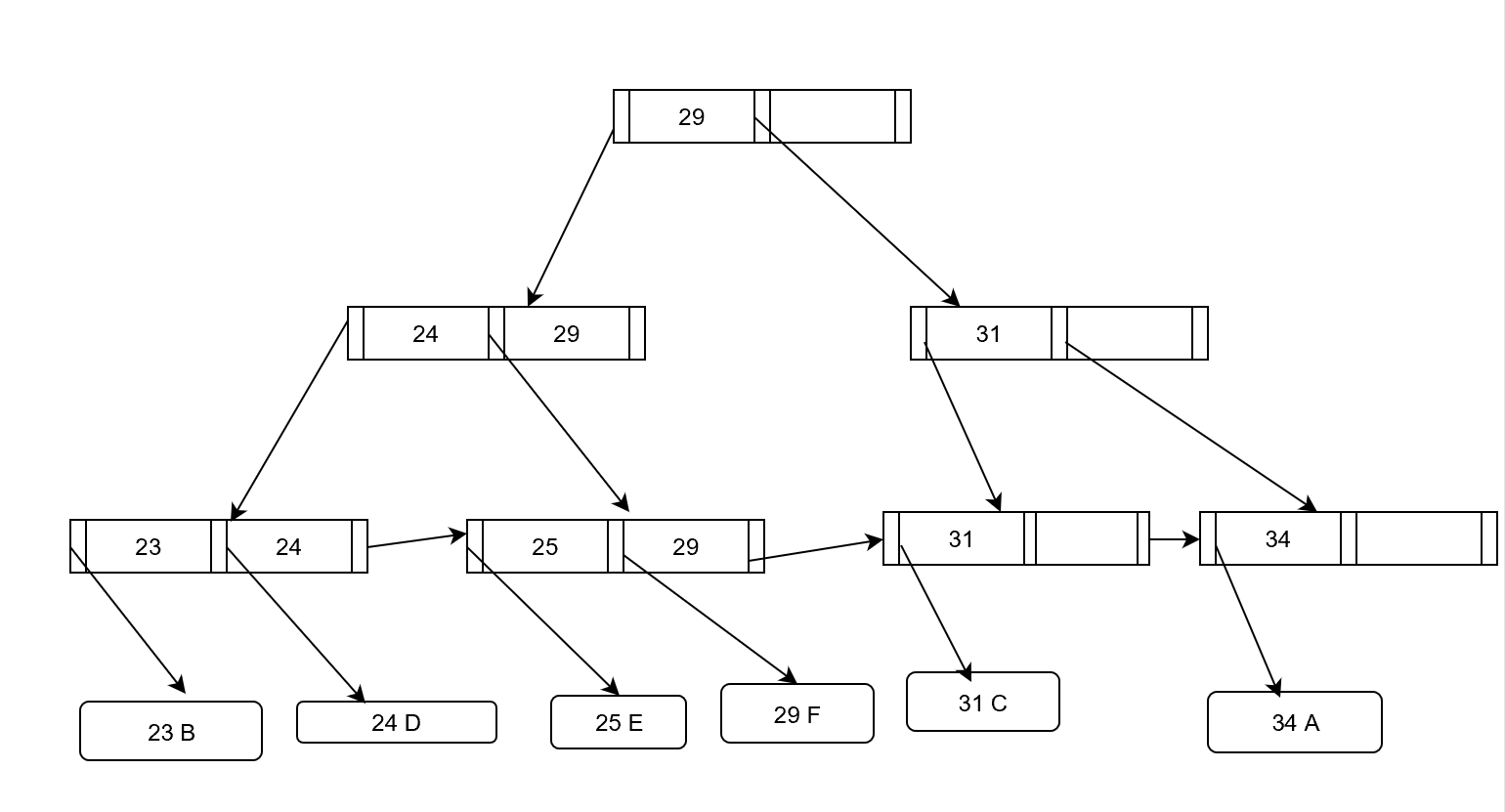
[29 F]を挿入(配置換えによるインデクス更新)
[25,31]
[23,24][25, 29][31, 34]





バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2018/01/23 02:31