こんにちは。
少し調べてみましたがどうやらphpQueryでは、HiruLowさんも苦心されたとおり、
子階層(のテキスト)まで取得しない
ようにするのが難しそうです。
ご質問にある、「ここだけ欲しい」のテキストだけ取ってくるには、
<div class="box"> の直下にあるテキストノード**だけ**を取得する
という指定ができる必要がありますが、phpQuery がサポートする
セレクタでは難しいようです。
どうしても、phpQuery で、ということになると、たとえば
html
1<div class="box">
2<p>ここはいらない</p>
3ここだけ欲しい
4</div>
だったら、<div class="box"> の text() で得られる
ここはいらない ここだけ欲しい
という文字列から、子要素の <p>ここはいらない</p> の text() で
得られる ここはいらない を差し引いて
ここだけ欲しいを得る、といった処理が必要になってきそうで、
とても面倒です。
このご質問で望ましい要素指定である「ある要素の直下のテキストノード」
という指定は XPATH ならできますので、XPATHをサポートする
DOMDocument
を使えば、以下のような感じで目的は一応果たせるかと思います。
php
1<?php
2
3$html = <<< HTML
4<div class='box'>
5<p>ここはいらない</p>
6ここだけ欲しい1
7</div>
8
9<div class='box'>
10ここだけ欲しい2
11</div>
12
13<div class='box'>
14ここだけ欲しい3
15<p>ここはいらない</p>
16</div>
17HTML;
18
19$dom = new DOMDocument;
20
21$html = mb_convert_encoding($html, 'HTML-ENTITIES', 'UTF-8');
22
23$dom->loadHTML($html);
24
25$xpath = new DOMXPath($dom);
26
27echo("<html><head><meta charset=\"utf-8\"></head>");
28echo("<body><ul>");
29
30foreach ($xpath->query('//div[@class="box"]/text()') as $node) {
31 if (strlen(trim($node->nodeValue)) > 0)
32 echo("<li>" . $node->nodeValue . "</li>");
33}
34
35echo("</ul></body></html>");
上記の PHP にブラウザからアクセスすると以下のようになります。
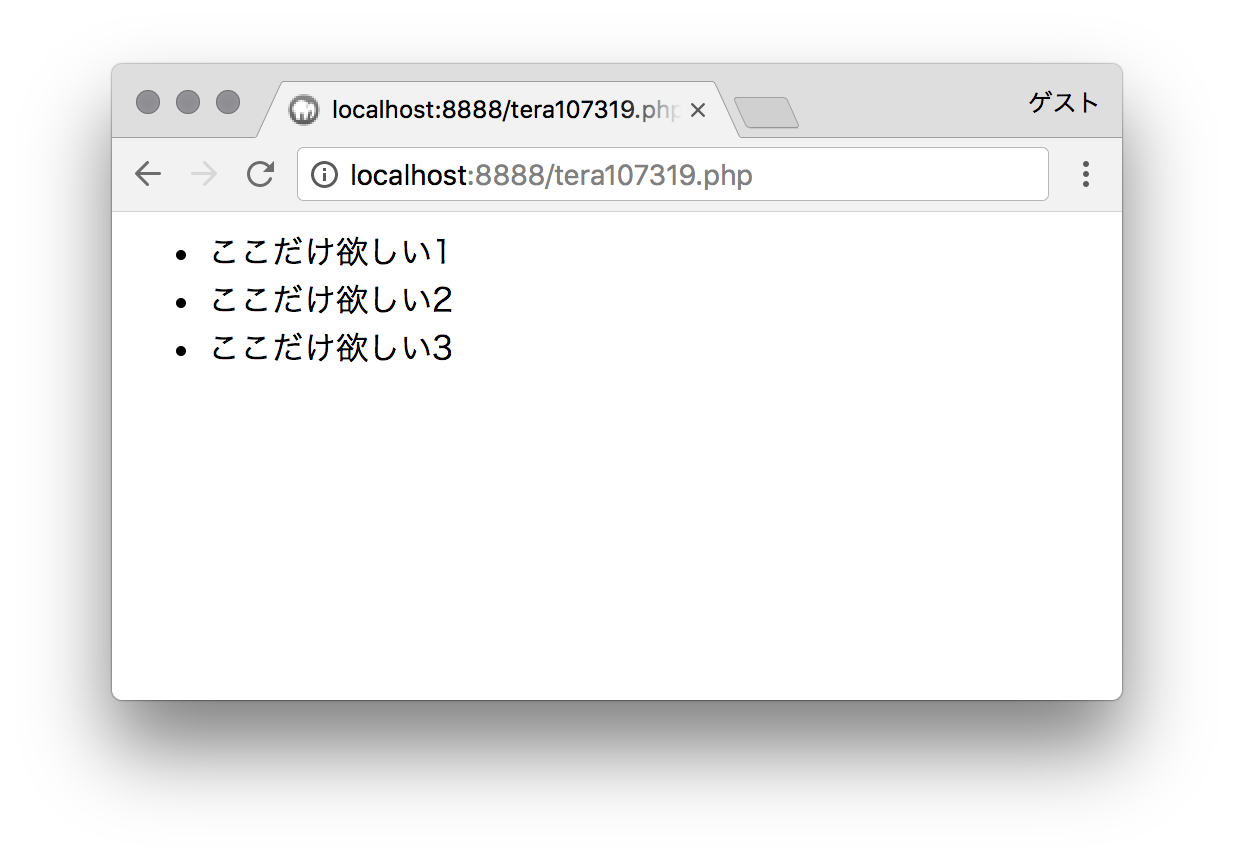
以上参考になれば幸いです。
追記
もう1案あるのですが、処理対象の HTML の中で、<div class="box"> と、
これの閉じタグである </div> が現れる行に何らかの規則があるのだったら、
HTMLパーサーを使わずに、HTMLを普通のテキストとして1行1行読んでいき、
この何らかの規則にそって、<div class="box">から </div> までの
複数行(あるいは1行)をひとつの文字列として取り込んで、あとは、
その文字列に対して正規表現で欲しい部分をキャプチャするという手もあると
思います。
上記で、「何らかの規則」と書いた具体例としては
たとえば以下のような2つのルールが考えられます。
-
<div class="box"> が出現するときは、必ず1行の中に入っている。
これはたとえば
html
1<div
2 class="box"
3>
のようになっていることはない、ということを意味します。
2. <div class="box"> の閉じタグ </div> の直後には <!-- end of box --> というコメントがある。
html
1</div><!-- end of box -->
上記は、あくまで、たとえばの話ですが、このようなルールがあれば、
<div class="box">・・・</div> を文字列で取り出すのは
それほど大変ではなく、文字列で取り出せさえすれば正規表現という
強力な武器を使えます。
※ただし、<div class="box"> の直下であれば、どの位置にあっても、
そのテキストノードを正規表現で取り出せるか?といえば、それは微妙です。
(いろいろ言ってすみません。)





バッドをするには、ログインかつ
こちらの条件を満たす必要があります。