

プログラムコードを示すときは、コードの前後の行に```を置いてください。特にpythonの場合インデントがちゃんと見えていないとチェックが困難です。
###前提・実現したいこと
任意の波形を組み合わせて 比較分析する際、データの検索や表示がエクセルでは重くなりすぎて扱いづらく、
Python・Pandas で解決できないか考えています。
具体的には、
データフレーム形式になっている多数のcsvファイルの中から
1列ずつ読み込んで任意の組み合わせで別のデータフレームを組み上げ、
最後にpandasのプロット機能で1つのグラフにしたい。
###発生している問題・エラーメッセージ
現在は1つのファイルの中から 欲しいカラムを1つずつ数字入力で選択することで
必要なデータだけデータフレームに格納して グラフ化するところまで完成している。
読み込む多数のcsvファイルが現在はすべて同じindexの値・個数となっているので今は問題ないが、
今後はファイルによって異なるindexを持つ場合に対応した形にしたい。
【 追記 】
異なるindexの説明が不足していたので追記します。
例えば
csv_A index_A column_A1,A2,A3,・・・
csv_B index_B column_B1,B2,B3,・・・
という2つのファイルから欲しいカラムを合わせたデータフレームを作ると、
df_A+B index_A+B column_A1,A2,B1,B2
のようになるとします。この状態でグラフ化すると index_A+B を すべてのカラムが参照することになってしまいますが、
A1,A2 は index_A を参照
B1,B2 は index_B を参照
するようにしたいのです。
実際のcsvファイルのindex_AとB は 実数の物理値で、
今扱っているデータだと Aのインデックス2つに対して Bのインデックスが1つとなっており、
しかも index_A2 (A2n) = index_B1 (Bn) のような関係でもあるので、
普通に結合して出来上がった データフレームは
colum_An で2個存在したのち、column_Bn の数値が1つ交互に格納されます。
このデータフレームをプロットすると以下のような状態になってしまいます。
column_An は 歯抜け (3回に1回データが存在しない)
column_Bn は 前半のプロットがない (前半は3回に2回データが存在しないので 線にならない)
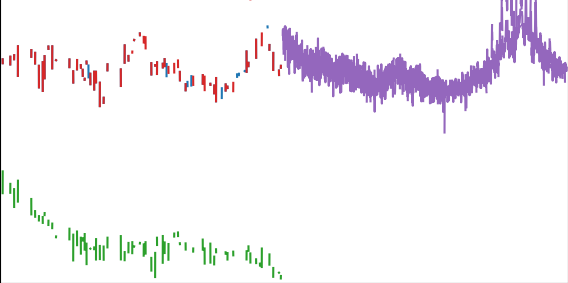
このような問題に Pandas あるいは Dataframe に良い解法はありますでしょうか?
【 追記2 】
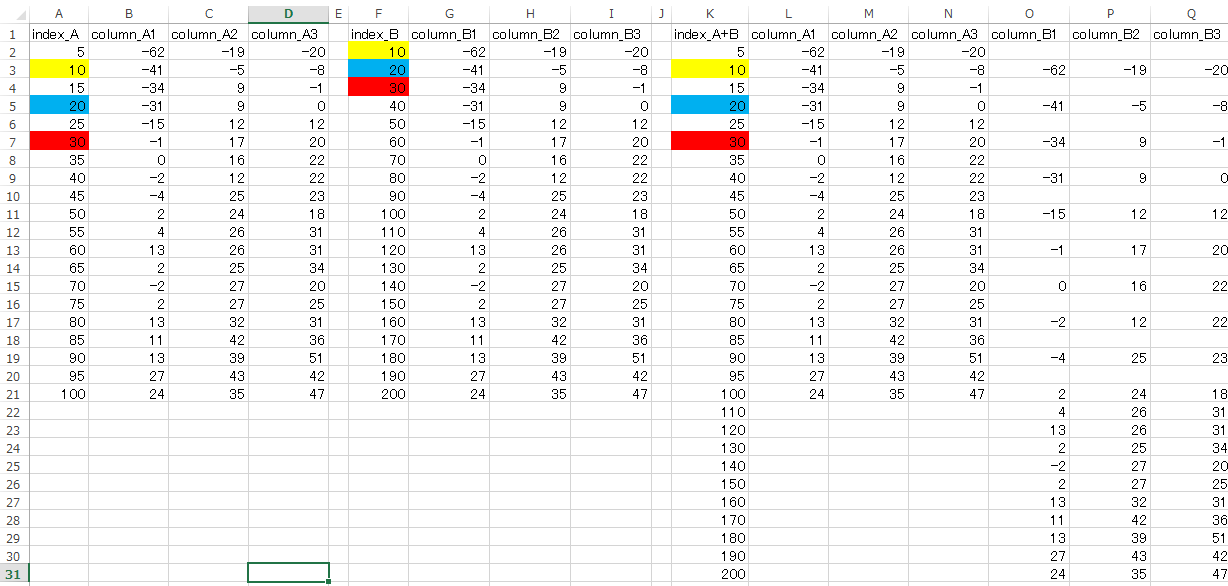
イメージですみませんが、それぞれの中身の一例を示します。
A~D : csv_A の 中身
F~I : csv_B の 中身
K~Q : df_A+B の 中身
K列 が index_A+B です。
今回の場合は index_A の 2個目と index_B の 1個目 が 完全同一のため index_A+B は
5,10,15,20,25,30,・・・
となりましたが、小数点以下が異なる場合、
5(A), 10(A), 10(B), 15(A), 20(A), 20(B), 25(A), 30(A), 30(B), ・・・
(A):元index_A、 (B):元index_B です。
のようになってしまうこともあります。
分かりづらくて申し訳ありません。
###該当のソースコード
# -*- coding: utf-8 -*- import pandas as pd import matplotlib.pyplot as plt # 読み込む CSVファイル を選択して データフレーム化する df1 = pd.read_csv('sample1.csv', index_col=0) # 繰り返し処理内変数 を 定義する mode = 1 # 処理状態 wcount = 0 # 処理回数 paned = pd.Panel({}) # CSVから取得した データフレーム から 必要なデータのみ選択して # 空のデータフレーム に 記載・追記する 繰り返し処理 while mode > 0: # 処理回数をアップさせる wcount = wcount + 1 # 取得した CSV から グラフ化したい 列(カラム)を 1つずつ 数値入力する print('指定カラムは?') innum = int(input()) - 1 # カウントが1のときのみ、取得カラムのインデックスを 空のインデックスに入力する # これだとカウント2以降でインデックスが変わる場合に対応できないため、暫定処理 if wcount == 1: df2 = pd.DataFrame(index=[df1.index], columns=[]) print(df2) print('') else: pass # データフレームに 選択したカラムとバリューを入力する # データフレームの追加処理、左辺でカラム名を、右辺でカラム名を除いたバリューを記載する df2[df1.columns[innum]] = df1.values[:,int(innum)] # データフレームにカラム・バリューを追記する処理 から 抜けるか、 # もう1回カラム・バリューを追加するかを選択する print('終了? ⇒ 0 継続? ⇒ 1') inmode = int(input()) # 選択結果から モードの値 を書き換える # 現状は 同じ CSV から 別のカラムを指定する場合のみ # CSVファイルを変える、CSVファイルのディレクトリを変える、などの処理を追加のこと if inmode == 0: mode = 0 else: mode = 1 df2.plot() # # グラフタイトレイアウト plt.tight_layout() plt.savefig("sample.png") plt.show()
###試したこと
1つのカラムだけで1つのデータフレームにすればインデックスも任意にできるが、
この場合だと複数のデータフレームを持つことになり、1つのグラフにまとめて表示できなかった。
###補足情報(言語/FW/ツール等のバージョンなど)
Python3.6、Pandas
Python歴2ヶ月で初質問のため、不作法などあるかもしれませんが ご容赦ください。
回答1件
あなたの回答
tips
プレビュー


